数据库的魅力-Mysql架构的探索
前述
数据库我们并不陌生,但是他又显得那么的陌生,为什么呢? 在编码中,我们可能通过ORM框架去链接数据库,例如利用Mybatis去写Sql,甚至我们直接用面向对象的框架JPA连Sql都不用去写,我们时时刻刻都在用它,一直从它那里获取结果,除了专业的DBA外,很少有人主动去了解它是怎么做的。
本博文将围绕对于数据库的CRUD,数据库又为我们做了哪些事情为主题来分析。本文采用Mysql 5.7版本举例
分层架构
Mysql采用分层架构设计,总体可以分为三层:
- 连接层
- 服务层
- 存储层
其中,连接层负责管理链接,权限验证等操作,服务层可以分为三层,首先负责对sql语句解析,然后经过Mysql底层规则,索引等优化后,根据执行结果进行返回,存储层就是Mysql的存储引擎,通过引擎存储到硬盘或者内存等介质。
连接的建立
先了解Mysql两个命令
- show status 查看mysql各种状态
- show variables 查看mysql各种配置属性
解释如名。
步入正题,不管我们通过PLSQL,Navicat等数据库工具还是ORM框架,首要的第一步就是对于数据库建立链接,Mysql提供两种类型的链接建立方式:
- 交互式链接
- 非交互式链接
交互式链接类似于用的Navicat链接工具,非交互式就是我们用的JDBC获取资源,当然不管哪种链接建立方式,都需要消耗系统线程去建立处理,势必会影响系统资源,所以Mysql给我们提供了两个参数配置来限制链接时长,分别为
show variables like 'wait_timeout'; -- 非交互式超时时间
show variables like 'interactive_timeout'; -- 交互式超时时间执行上述Sql后结果分别为:
| Variables_name | Value |
|---|---|
| wait_timeout | 28800 |
| interactive_timeout | 28800 |
由此说明Mysql不管什么方式进行链接,默认无操作超过28800秒(即8小时)后就会被强制断开链接。
另外,系统线程数量也是有限的,Mysql不会让你无限制的建立链接,所以在数量上也有限制,我们通过下面命令可以得到Mysql当前链接允许的上限
show global variables like 'max_connections'我们会得到结果:
| Variables | Value |
|---|---|
| max_connections | 151 |
说明我们当前设置的最大链接上限为151
另外,大家发现没,如上面sql相比,多了global关键字, 其实Mysql在参数设置与查看上存在两种级别:
- session: 会话级别,只对当前链接/窗口有效
- global: 全局级别,对全局有用
而且并不是每个variables都可以在这两种级别环境设置,就比如我们刚才使用的max_connections就只有global级别
SQL语法预处理
既然要执行Sql,那么SQL的语法是否可被执行,就是通过Mysql的语法解析器与预处理模块来处理了
我们已执行个简单的sql为例
select blog_name from blog where blog_author = 'timeroar' and blog_title = '数据库'Mysql在执行上面的Sql之前,它要知道写的是什么,并且要了解意思,这是一个最基本的功能,mysql的语法解析是对语法进行打碎并生成语法树,如下
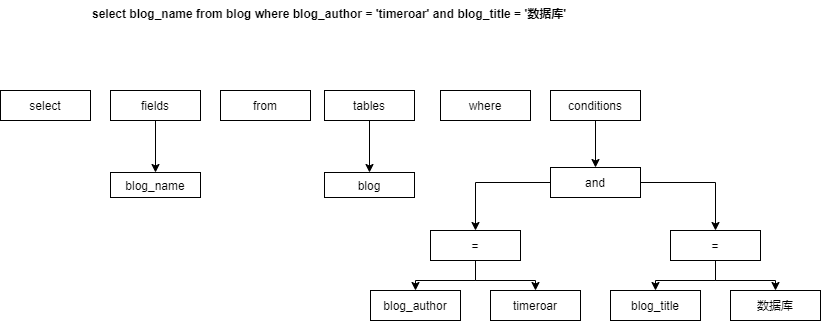
语法解析完了,接下来就要分析正确性了,mysql会对语法树上的字段名,表名进行检索,判断是否存在,这个功能,就是Mysql的预处理功能。
执行计划与优化器
我们的sql并不是只有我们在书写过程中可以优化sql逻辑,mysql的底层在预执行之前也会根据一系列复杂的算法帮我们优化sql,比如连接的消除,语义的优化等等逻辑, 但是我们并不能完全的依赖于优化器,经过优化器后会生成一个执行计划,我们可以通过explan关键字获取sql查询计划,例如下面的语句
EXPLAIN select * from sys_user us left join sys_users_roles r on r.user_id = us.user_id我们可以得到执行结果:
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | us | ALL | 2 | 100 | ||||||
| 1 | SIMPLE | r | ref | PRIMARY | PRIMARY | 8 | teacher.us.user_id | 1 | 100 | Using index |
explain
先介绍下explain每个字段的含义
-
ID: id代表执行select语句或者操作表的顺序, 如果ID相同,则ID相同的为一组从上至下依次执行,如果ID不同,则ID从大到小依次执行
-
select_type: 查询类型,一共有六种分别是:
- SIMPLE: 简单查询, 查询不包含复杂查询逻辑,如UNION
- PRIMARY: 当查询中包含复杂的子部分时,最外层查询会被标记为
PRIMARY - SUBQUERY: 查询字段或者where条件中包含子查询
- DERIVED: from列表包含的子查询
- UNION: 当select出现在UNION之后,会被标记为UNION
- UNION RESULT:UNION后获取结果的SELECT
-
table: 指当前操作的表,或者
DERIVED标记的临时表。 -
type: 表示查询使用了哪种类型,类型如下:
- system: 系统表范畴,表中只有一列数据的时候可能会出现
- const: 通常为主键或者unique唯一索引进行条件比较查询, 表示一次就能索引到的数据,例如
where id = 1 - eq_ref: 通常为主键或者unique唯一索引进行记录扫描,表中有且只有一条记录与之匹配, 关联条件可见,如
user.id = role.id - ref: 与eq_ref的区别是,它是非唯一性索引扫描,返回匹配的所有行。
- range: 给定范围进行索引列的索引,如where条件中使用in、between等关键字对主键ID进行范围查询
- index: 全表扫描,但是查询字段为索引字段时
- all: 全表扫描,但是查询字段为非索引字段
效率上从最好到最烂依次为
system > const > eq_ref > ref > range > index > all,工作中查询语句一般至少要达到range级别 -
possible_keys: 可能存在的索引,查询字段存在索引,则会在这里显示,但是并不一定被使用
-
key: 实际会使用的索引,如果为
NULL,则表示没有用到索引,或者索引失效, 当通过索引查询索引字段时,如select id from user where id = 1, 此时并不会在possible_keys中显示,而直接在key中显示。 -
key_len: 索引中使用的字节长度,值为索引字段的最大可能长度而不是表中实际数据长度,再不损失精确度的情况下,长度越短越好。
-
ref: 索引被引用的列
-
rows: 根据预信息统计即索引使用情况,得出如果得到我们所需要的结果,需要使用多少行数据。
-
Extra: 当前表对于其他表没有显著作用给出来的额外提示信息,它有以下几类信息
- Using filesort(九死一生): 出现这个标志意味着你的sql需要优化,因为mysql无法利用索引来完成排序操作,需要对数据使用一个外部的排序操作
- Using temporary(十死无生):使用了临时表来存储中间过程数据,必定影响效率,需要优化
- Using index 用到了覆盖索引, 如果同时出现了
using where,表明索引被用来执行索引键值的查找,反之表明索引用来读取数据而非执行查找动作。 - Using where :使用了where查询语句
- impossible where: where 结果永远为
false - Using join buffer: 使用了链接缓存



